ZRAMを正しく設定すれば、4GBメモリのVPSを体感6GB〜10GB相当まで引き上げられます。(ChatGPT曰く)
本記事では、Ubuntu/Debian系でZRAMを導入し、実質2.5倍を狙う具体手順をハンズオン形式で解説します。
ZRAMとは?(超かんたん解説)
ZRAMはメモリ上に圧縮スワップを作る仕組み。
→ 同じ4GBでも「圧縮」することでより多くのデータを詰め込める。
-
速い:ディスクスワップより圧倒的に高速
-
安い:設定するだけ
-
現実的:1.5〜2.5倍が狙える(ワークロード次第)
実質2.5倍を狙う設計(考え方)
前提
-
物理メモリ:4GB
-
ZRAMサイズ:4GB(= 物理メモリと同サイズ)
-
圧縮率目標:2.5倍
→ 理論上:4GB + (4GB × 2.5) ≒ 10GB相当
※ 実データの圧縮率に依存。テキスト/キャッシュ多めなら達成しやすい。
ハンズオン:ZRAMを導入する(Ubuntu / Debian)
① 既存スワップの確認(念のため)
※ 既存のディスクスワップがあってもOK。ZRAMを優先させる。
② ZRAMツールをインストール
③ 設定ファイルを編集(2.5倍を狙う構成)
以下に設定:
意味(超重要)
-
ALGO=zstd
→ 圧縮率と速度のバランスが良い(2.0〜2.8倍狙える) -
PERCENT=100
→ 物理メモリと同サイズのZRAM(4GBなら4GB) -
PRIORITY=100
→ ディスクスワップよりZRAMを優先実際にやってみた(メモリー2GB)
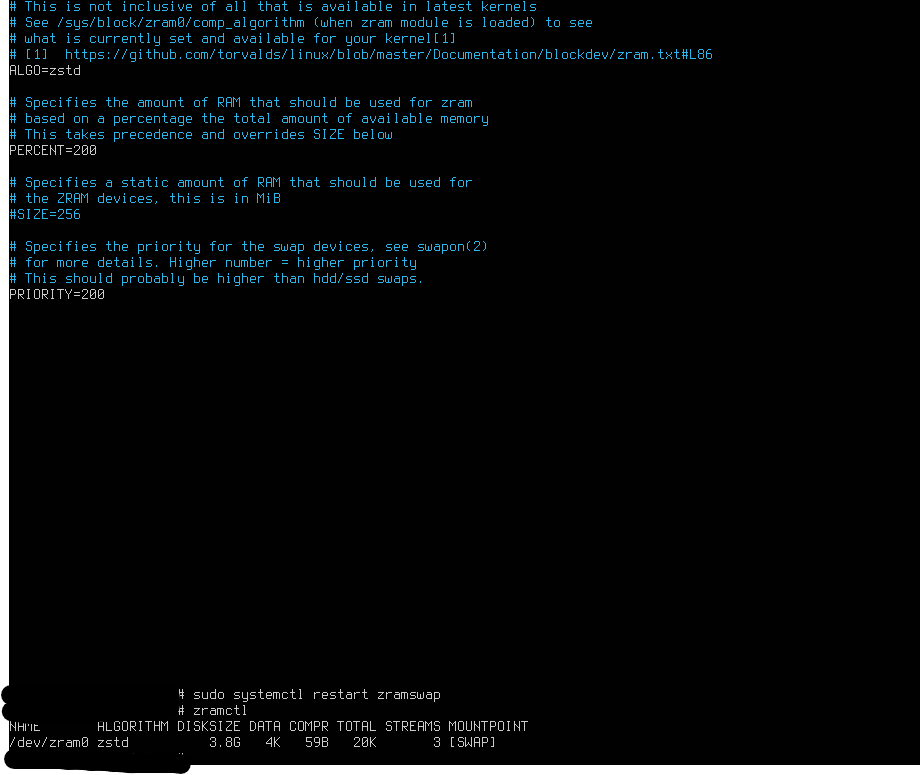
項目 意味 今の状態 ALGORITHM 圧縮方式 zstd(OK) DISKSIZE ZRAMのサイズ 3.8GB(ほぼ4GB) DATA 実データ量 4KB(ほぼゼロ) COMPR 圧縮後サイズ 59B(誤差レベル) TOTAL 管理用含む 20KB MOUNTPOINT 用途 swap
-
ZRAMがちゃんと効くかテストする(安全な負荷テスト)
「本当に圧縮できるか」試すなら👇
「実質10GB」になってるか?現実ライン
今の圧縮率が維持できた場合の理論値:
-
ZRAM 3.8GB × 4.4倍 ≒ 16GB相当(理論上)
-
ただし、これは軽いデータが多いから出てる数値
ここからはメモリー増やした状態でこのVPSをLLMサーバーにしてみたいと思います。
対象:
-
Ubuntu Server
-
物理RAM:2GB
-
ZRAM:有効
-
目的:とりあえずLLMが動くこと
使うモデル:
Phi-3 mini 1.5B(Q4量子化 / GGUF)
→ 超軽量・実用レベル・2GB環境の現実解① 依存関係インストール
② llama.cpp をビルド(CPU版)
※ AVX2対応CPUなら自動で最適化される
※ 非対応でも動く(遅いだけ)③ 軽量モデルをダウンロード
※ サイズ:約1GB
※ 2GB + ZRAM環境の現実ライン④ サーバーモードで起動(GUI不要)
パラメータ解説(重要)
オプション 意味 理由 -c 1024コンテキスト メモリ節約 -t 2スレッド CPU 3コア想定 --host 0.0.0.0外部公開 APIで使う --port 8080ポート お好み ⑤ 動作確認(VPS内)
okが返れば成功 🎉 -
⑥ 推論テスト(API叩く)
👉 数秒〜十数秒後に日本語で返ってくれば成功
ELYZA-tasks-1.1B GGUF(日本語特化・軽量)
起動:
👉 これで ちゃんと日本語が返るはず。
今の環境は “Hugging Faceの直wgetが全部401で弾かれる” 設定 になってる。
(IPv6経由 or 事業者IP帯が弾かれてるパターンが多い)
hf download bartowski/Meta-Llama-3.1-8B-Instruct-GGUF Meta-Llama-3.1-8B-Instruct-IQ2_M.gguf --local-dir .
No local file found. Retrying..
Meta-Llama-3.1-8B-Instruct-IQ2_M.gguf: 4%|█▋ | 122M/2.95G [02:00<58:45, 802kB/s]Killed
よく使うモデルを入れてみよと思ったけど・・・メモリー不足でダメ・・・LLMは難しい・・・
コメント (0)
まだコメントはありません。最初のコメントを投稿してください!